Avez-vous déjà consulté un rapport de langue des utilisateurs dans Google Analytics? Avez-vous, vous aussi, été dérouté(e) par toutes ces valeurs bizarres qui se ressemblent toutes? Cet article vous montre comment rationaliser ces codes langues pour les rendre lisibles – ou en tout cas vous mettre sur le bon chemin 🙂
Voyons voir quelle langue est la plus utilisée… MAIS C’EST ILLISIBLE?!
Commençons par la base et examinons le joyeux bazar du rapport Google Analytics Audience > Données géographiques > Langue:
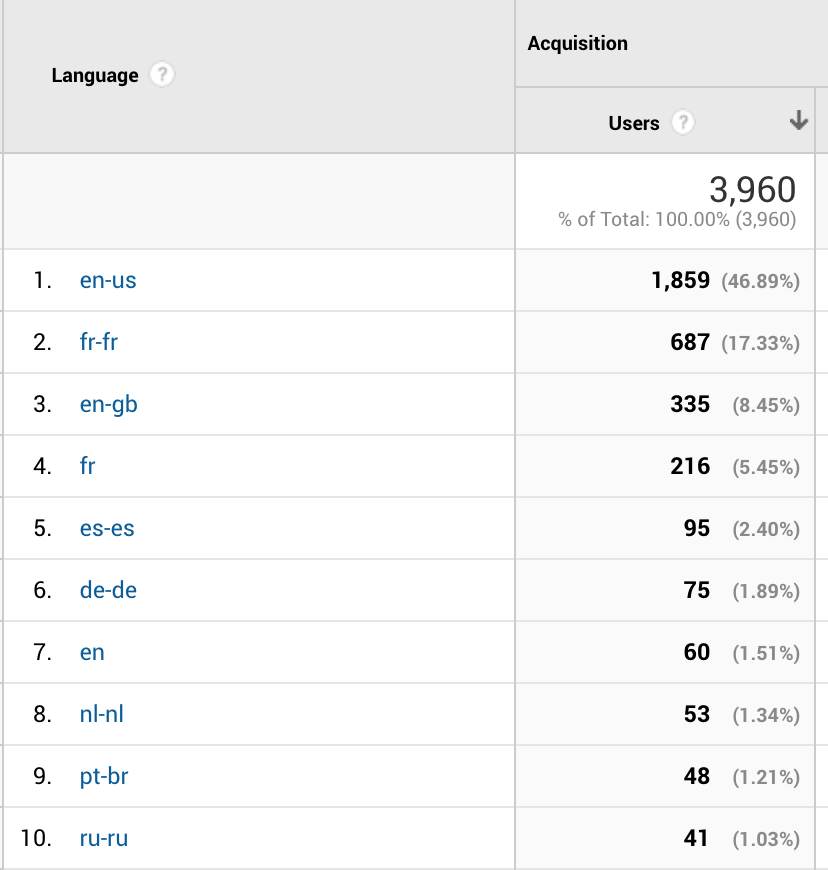
On y trouve beaucoup de valeurs, sensées adopter la norme ISO-639-1 pour les codes de langue. Pour référence, ISO-639-1 utilise un code de langue sur 2 lettres tel que en pour l’anglais et fr pour le français. Ce qui est clair, facile et devrait être mis en œuvre partout, n’est-ce pas?
Ca devrait être le cas – sauf dans les navigateurs Web qui eux utilisent des versions dérivées de la norme 639-1 en ajoutant un code local. Par exemple, en-gb est pour l’anglais de Grande-Bretagne. De la même façon on distingue le français de France (fr-fr ou fr_FR) du québécois (fr-ca ou fr_CA). Ceci est dû à une spécification pour les navigateurs et les serveurs Web basée sur le contenu linguistique qui doit être accepté et servi. Pourquoi s’embarrasser de standards, après tout, hein?
En admettant que vous souhaitiez faire le ménage dans vos rapports de langue, voici un filtre rapide qui vous permettra de tout remettre à plat.
Creation du filtre sur le code langue
Rendez vous dans votre console Google Analytics puis allez dans l’admin au niveau de la vue dans laquelle vous souhaitez créer le filtre.

Cliquez sur le gros bouton rouge « Ajouter un filtre » et commencez à créer le filtre en utilisant la définition ci-dessous:
Assurez vous de bien choisir un filtre personnalisé de type avancé.

L’expression régulière du champ A recherche les 2 premières lettres du code de langue et les isole en écrasant le champ du code langue. Le paramètre $A1 fait référence au contenu du premier jeu de parenthèses du champ A. Cela signifie que tout code langue étendu se normalisera avec le temps.
Comme avec la plupart des fonctions de Google Analytics, ce filtre n’est pas rétroactif. Cela signifie que pendant un certain temps, vous aurez des rapports comprenant à la fois des codes langue abrégés, standard et conformes aux normes ISO639-1 ainsi que les absurdités ab-cde-wtf que vous avez pu observer par le passé.
En conclusion
En fait, même après la mise en place de ce filtre, je ne vous promets pas que vous utiliserez Audience > Données géographiques > Langue davantage que maintenant. Et là, je sens la confusion monter en vous, à juste titre.
En tout état de cause, vos données de code langue seront propres et lisibles après la mise en place du filtre, presque utiles – mais pas forcément. Pourquoi? Parce qu’il s’agit d’un rapport détaillant la langue du navigateur – ce qui fait que mes menus sont en français par exemple – mais pas la langue du contenu consulté dans le navigateur.
Pour être honnête, le rapport sur les codes langue pourrait m’indiquer par exemple une appétance pour mon contenu par des visiteurs au navigateur en Chinois, alors que mon blog est en anglais et en français. Cela dit je n’ai aucun moyen de savoir s’ils utilisent une extension de navigateur telle que Google Translate. Devrais-je commencer à poster en Mandarin? 🙂
Le plus utile serait de corréler mes nouveaux rapports de code langue (désormais bien propres sur eux) avec la consommation de contenu dans une langue particulière. C’est là que je commencerais à tirer des « enseignements » de ce genre de rapports.
Et vous? Examinez vous vos rapports de code langue? Les utilisez-vous tels quels ou passez-vous par un traitement externe?
Faites moi signe dans les commentaires!!
Salut Julien,
Merci pour cet article! Une idée de comment faire la « même » maniclette dans Data Studio? L’idée serait de compiler les langues pour n’avoir qu’un code, mais j’ai beau chercher, je trouve rien 🙁 Merci!
Sacha
Bonjour Sacha,
pour ca, il faut créer un champ calculé dans la source de données Data Studio. L’occasion d’un autre article 🙂